团队简介
团队项目:通用神经网络处理器下的核内调度
参赛赛题:A组赛题—通用神经网络处理器的核内调度问题
获奖情况:全国一等奖
培养单位:机械与动力工程学院、管理学院
团队名称:郑州大学研创队
团队成员:李功平、杨龙、张丽娜
指导老师:魏伟、梁静
团队风采

李功平(队长)
李功平,郑州大学机械与动力工程学院2023级博士研究生,研究方向为调度优化。

张丽娜(队员)
张丽娜,郑州大学管理学院2024级博士研究生,研究方向为决策与优化、旅游决策。

杨龙(队员)
杨龙,郑州大学管理学院2023级硕士研究生,研究方向为政策智能、大语言模型、文本挖掘。获得2025年研究生国家奖学金、河南省三好学生、郑州大学三好研究生等荣誉。

魏伟(指导老师)
魏伟,管理学院副教授,郑州大学青年骨干教师,长期致力于政策智能与大模型垂域应用的教学与科研工作。河南省碳中和研究院执行院长、郑州市资源环境大数据与智能决策重点实验室副主任、黄河流域资源环境经济协调发展研究中心副主任、《煤炭经济研究》期刊青年编委。发表学术论文60余篇,1篇论文入选全球1%的“ESI高被引论文”、2篇论文为郑州大学TOP论文;曾获河南省教育厅科技成果一等奖、河南省高校哲学社会科学优秀成果三等奖。主持1项国家自然科学基金青年项目,4项省部级项目;参与1项国家社会科学基金重大项目,1项国家社科基金一般项目,2项国家自然科学基金面上项目及2项省部级项目研究工作;参与出版著作1部。

梁静(指导老师)
梁静,电气与信息工程学院二级教授,国家优秀青年科学基金获得者,IEEE Fellow,长期致力于群体智能优化算法设计及其应用的教学与科研工作。谷歌学术总引用超过30000次,在全球进化计算领域排名第27位(全球女性第2位,华人女性第1位);单篇最高引用达4500余次,位居2017年全球进化计算领域十年高被引文章首位。已连续五年入选爱思唯尔“中国高被引学者”及全球前2%顶尖科学家榜单。曾获颁IEEE计算智能学会优秀博士论文奖(全球每年仅1名)、教育部自然科学奖二等奖、中国仿真学会自然科学奖二等奖,并获评中科院一区Top期刊IEEE Transactions on Evolutionary Computation的Outstanding Associate Editor。
作品介绍
1.作品背景
基于单指令多数据流(Single Instruction Multiple Data,SIMD)架构的AI芯片因硬件设计简单、相同工艺下单位芯片面积能实现的计算能力更高而广泛应用于移动及物联网设备。在神经网络推理过程中,算子(如矩阵乘Matmul、卷积Conv、注意力Attention等)是最小任务单元,其执行效率直接影响模型在平台上端到端的推理性能。目前,企业将算子在SIMD架构硬件平台上的完整计算过程拆解为由硬件单元操作构成的细粒度计算图,并通过手工或依靠规则启发式的方式编排成可在SIMD平台上执行的任务。由于这类计算图具有高度异构性(算子类型多样、输入形状动态变化、拓扑结构复杂),编排方式难度大,缺乏通用性,且效率低下,无法在如今日益复杂的计算场景下大规模推广。因此,亟需设计一种通用调度算法,自动地将计算图中各原子操作编排调度到各硬件单元上执行,取代低效的人工编排计算单元流水的过程。
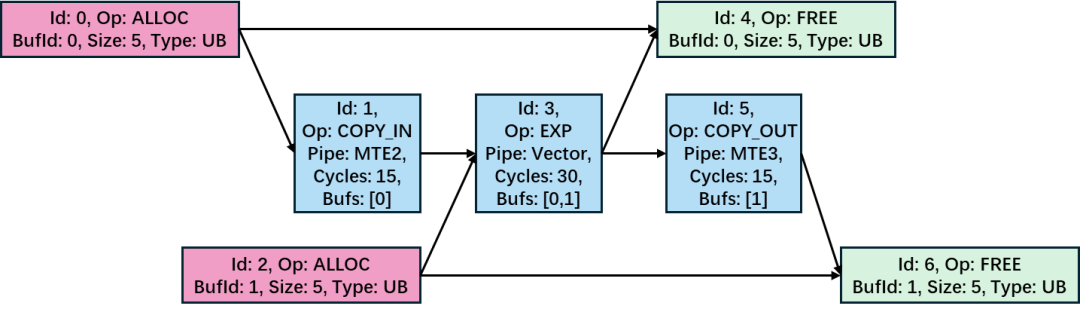
图1 计算图示例
2.作品简介
针对通用神经网络处理器的核内调度问题,作品提出一种递进式优化方案,其目标依次为:最小化驻留的最大缓存容量、最小化总核外数据搬运量,最终实现总运行时间的最优化。方案以三类共六个典型计算图(Matmul_Case0/1、FlashAttention_Case0/1、Conv_Case0/1,节点规模介于1716至36086之间)为研究对象,通过三个阶段系统解决核内调度问题。
问题一:最小化驻留的最大缓存容量
本问中针对最小化驻留最大缓存容量的优化目标,设计了相应的图模型解析与优化框架,求解出优秀的调度序列。首先解析节点的操作类型(ALLOC/FREE/COMPUTE等)、缓冲区层级(L0A/L0B/L0C/L1/UB)及内存变化量,通过前向和反向拓扑遍历计算关键路径信息(最早开始时间、最晚开始时间、松弛度)。针对L0缓冲区"同类型同时只能存在一个活跃缓冲区"的硬约束,建立了ALLOC-FREE配对映射和依赖路径追踪机制。初始解生成采用基于关键路径的贪心调度策略,设计了多层优先级体系:待释放L0节点最高优先级,就绪节点中L0 FREE操作优于普通FREE,计算节点根据是否在关键路径、松弛度和内存分配量分层排序,并动态维护活跃L0状态和待处理队列。优化阶段采用变邻域搜索算法,集成交换、插入、块移动三种邻域结构进行迭代寻优,最终实现了从初始解到优化解的改进。
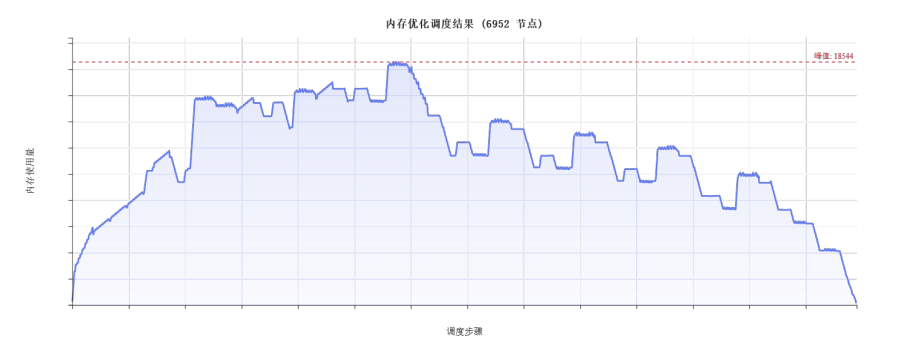
图2 Conv_Case1任务中最大缓存容量变化
问题二:最小化总核外数据搬运量
本问中针对多级缓存的内存分配与SPILL优化问题,构建了动态分配与验证框架。首先解析地址空间不重叠约束、各级缓存容量限制(L0A/L0B/L0C各256/512字节,L1为4096字节,UB为1024字节)以及SPILL_OUT/SPILL_IN节点的依赖关系与属性约束。目标函数综合最小化总额外数据搬运量(考虑COPY_IN使用情况的代价权重)与减少缓存碎片化。核心算法采用生命周期感知的分段分配策略:长生命周期缓冲区(距释放超过25步)优先分配低地址以提高稳定性,短生命周期缓冲区分配高地址以加速释放后的空间合并。SPILL选择策略集成邻接合并优先和加权优先级双重机制,邻接合并通过构建内存映射寻找可合并的连续溢出集合,加权优先级综合下次使用距离、COPY_IN代价因子和缓冲区大小进行排序。空闲空间管理采用堆结构维护分段列表,支持动态合并相邻空闲段以减少碎片。算法时间复杂度为O(n·log(m)),其中n为节点数, m为活跃缓冲区数。

图3 Conv_Case0任务的L1的部分缓存分配变化
问题三:最优化总运行时间
本问中针对计算图的缓存分配与调度联合优化问题,构建了基于偏好感知与自适应反馈的迭代优化框架。首先解析缓存生命周期(分配至释放区间)、关键路径节点(松弛度为零)、缓存复用依赖关系(串行依赖指同类型缓存通过依赖边连接、并行冲突指不同类型缓存无依赖关系)以及节点操作的并行与串行特性。目标函数综合最小化总执行时间(考虑计算周期与数据搬运延迟)和总额外数据搬运量(SPILL操作代价)。核心算法采用自学习启发式策略:初始解生成阶段融合关键路径优先级与动态反馈调整,通过PreferenceFeedback机制对关键路径节点施加优先级提升,对非关键大缓存施加溢出偏好。分配阶段实现偏好感知的缓存管理,优先复用串行依赖缓存的地址空间,避免并行缓存的地址冲突,对关键路径缓存强制分配以避免等待。SPILL选择策略集成级联防护机制,限制单个缓存的最大溢出次数,通过追踪溢出历史并动态调整选择得分。时间线分析器计算执行单元占用与依赖约束下的节点开始/结束时间,识别关键边并反馈至下轮迭代。迭代优化过程记录收敛轨迹与帕累托前沿,通过分析时间线中的关键路径与SPILL节点分布,动态生成反馈约束(避免溢出关键缓存、提升关键计算节点优先级),实现解空间的自适应搜索。验证模块通过逐步执行调度序列模拟缓存分配,确保解的可行性,算法在多目标优化空间中平衡执行时间与溢出代价,最终实现了对初始解的显著改进。
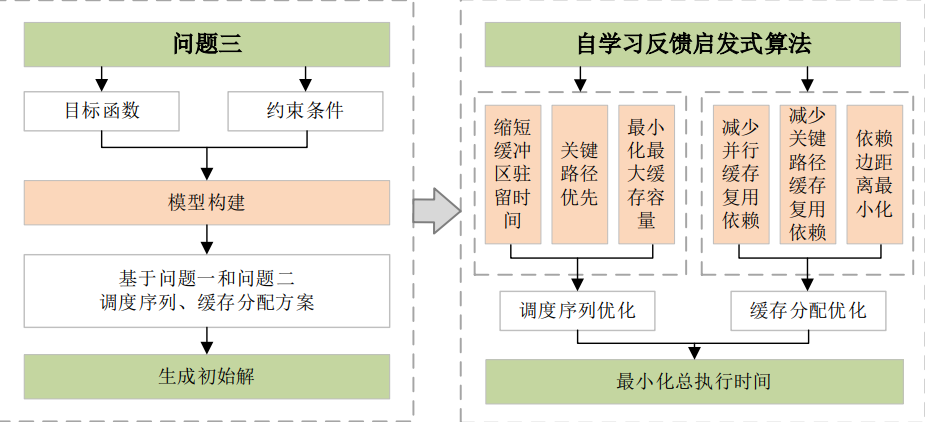
图4 问题3研究思路图
创新点
1.多阶段启发式融合与自适应优化机制
问题一采用关键路径贪心(利用earliest_start/latest_start/slack计算节点紧迫度)构建初解,结合变邻域搜索(集成swap/insertion/block_move三种邻域)进行全局寻优。问题二采用生命周期感知分段分配(长生命周期优先低地址、短生命周期优先高地址),配合邻接合并与加权优先级的混合SPILL选择策略。问题三引入自学习反馈机制,通过时间线分析器识别关键路径,动态生成优先级调整与溢出偏好,实现“调度→缓存→时间线→反馈”的闭环自适应优化,同时设计级联防护机制,通过追踪溢出历史并动态调整得分,避免溢出连锁反应。
2.分层优先级与偏好感知的精细化调度策略
构建五层级优先级体系:待释放L0节点最高优先级(-100),就绪节点中L0 FREE(-10)>普通FREE(-9)>关键路径计算节点(-8)>常规计算节点(-7),每层内部按松弛度与内存分配量细化排序,精准匹配NPU的L0缓冲区“同类型同时仅1个活跃”硬约束。将缓存复用关系分类为串行依赖(同类型+依赖边)与并行冲突(不同类型+无依赖),设计三级分配策略:优先复用串行缓存地址(+10.0分)、避开并行缓存区域(-5.0分)、关键路径缓存强制分配。结合生命周期感知地址选择与reuse_candidates追踪,实现多维度精细化管控,有效减少数据搬运代价与缓存碎片化。
3.分阶段协同优化与多场景工程验证
遵循“先降峰值内存→再优化地址分配与溢出→最后联合优化执行时间”的三阶段递进框架,各阶段优化互为基础,形成“内存→地址→性能”的协同提升链条。问题一通过VNS将初始峰值内存降低7.6%-27.3%;问题二在固定调度下优化缓存分配,平衡溢出次数与地址冲突;问题三在多目标空间中迭代寻优,通过帕累托前沿跟踪实现持续改进。在6类典型计算图上验证,覆盖矩阵乘、注意力机制、卷积运算等算子类型与1716-36086节点的小中大规模场景,结果表明算法在不同节点规模、边密度、缓存配置下均收敛,展现良好的通用性。
团队寄语
1.细审题目,锚定约束
我们曾因遗漏注释中“L0缓冲区同一时刻仅1个活跃”的约束,导致调度算法近乎返工,耗费双倍时间。这警示“慢即是快”:编码前需团队共理硬约束(如地址、依赖)、软目标(如内存、时效)及数据细节,用清单逐项确认,规避返工风险。
2.先求完整,再谋优化
面对多问联动赛题,“先通后优”策略成效显著:首轮快速实现基础算法确保流程可运行,第二轮迭代优化并保存中间结果。该策略既保障时间紧张时能提交完整解,又预留优化空间。建议40%时间用于审题与基础实现,60%用于优化,同步完成文档与复核。
3.善用工具,保持独立
文档协作上,Word易现格式混乱、版本冲突,转PDF还可能丢失图片,Overleaf的实时协作与版本管理更适配需求。AI工具可辅助搭建代码框架、润色文档,但核心算法逻辑需手动设计——AI生成代码难精准理解复杂逻辑,易藏隐患。应将AI作“助手”,明确其擅长与短板,取长补短提升效率。
结语
这是一次难得的经历, 48个小时的全身心投入让我们深刻体会到团队协作的力量:算法设计的灵感碰撞、文档撰写的分工协作、攻克难关的相互支持,每个环节都凝聚着集体智慧。从最初面对芯片背景的茫然,到最终实现峰值内存降低27.3%、执行时间优化的突破,这个过程不仅是技术能力的提升,更是信息搜集、问题分解、抗压能力、时间管理等综合素质的锻炼。
诚挚地建议大家积极参赛:这不仅是一场展示实力的舞台,更是一次迅速成长的契机。无论结果如何,三个人并肩全力以赴的过程本身,就是最珍贵的收获。愿每一位参赛者都能感受到协作带来的心意相通、专注带来的心流体验、突破难关带来的念头顺达,在数模竞赛的舞台上绽放属于自己的光彩!
